
If you’re reading this, you’re probably already familiar with Plus One Robotics’ Human-in-the-Loop (HitL) automated warehouse robotic pick and place system. It’s been in production for 7+ years now, and has completed nearly two- billion picks. Generally, it works really, really, really well.
But times and technologies change. Before I tell you about our most recent experiments, let’s revisit the early days of PickOne and Yonder. Back in 2019, when Avengers: Endgame was in theaters, “Game of Thrones” was ending, and we had not yet heard of COVID-19.
PickOne was, and still is, an automated vision system for warehouse pick and place logistics. It is the “brain” that connects the eye (camera) and the hand (industrial arm with multi-suction-cup gripper), directing the system where to reach to pick up items for induction or depalletization. As a deployed system, we always knew that there would be some scenarios that PickOne would be unable to handle, given the ever changing, volatile world of shipping and packaging.
Before Yonder (our HitL solution), all autonomy failures required a human to physically walk out to the cell and resolve the underlying issue (remove a difficult package, purge garbage off the conveyor, etc). Resolution time was measured in minutes, with most of that being the transit time or the amount of time it took the person to physically get to the cell.
Many of the issues were actually difficulties with the system’s vision – A new kind of package was introduced, or a particularly confusing arrangement of items showed up. These scenarios are easy for a human to resolve, if only they could arrive on the scene faster.
With Yonder, we connected struggling autonomous systems with remote humans,Crew Chiefs, in seconds, rather than minutes. For vision problems, this means the system can be back up and running before a human could even get to the cell physically.
In addition to resolving issues more quickly, Yonder gives us visibility into the types of issues that are happening, and their relative frequency, allowing us to focus our efforts to improve what matters most. Specifically, we could see how packages were changing, and which ones were the most difficult to manage, and adjust the algorithms accordingly. Once we moved to a machine learning-based approach, we could use this captured data in a continuous learning cycle to improve our models. We even developed the Single Annotation Paradigm to use the Human Crew Chief derived data directly, without needing additional (time consuming) manual annotation, leading to a fully automated self-improvement process.
But even with better models coming out at a regular cadence, we had production issues. Namely, updating the on-board models requires us to coordinate with the end-user and their schedules, and our newer models are sometimes incompatible with our seven year old hardware.
To address these issues and take greater advantage of improvements in model architecture, increased available GPU performance, networking capability, and cloud computing, we launched the AI-CrewChief-in-the-Cloud project (AICC).
The project goal is simply stated: can we use the same data that we’re already collecting to train a more capable model that lives in the cloud and takes some of the burden off of our human crew chiefs?
Note, Crew Chiefs actually solve three different, yet related, problems:
- Object detection/segmentation:This is the same problem that our on board model solves – Determine the boundary or mask of pickable objects.
- Pick Ordering:Given a bunch of potential pickable objects (from the above step), choose which one to pick next. This is a complex problem, although we have some heuristics to help. Generally speaking, higher up packages should be picked before lower down ones, and packages closer to the outbound conveyor belt should be picked before ones further away. On-board, this problem is solved by our custom algorithms. However, they sometimes fail and need human support.
- Fault detection:Our humans are still the best line of defense against unexpected faults, such as packages spilling, belts tearing, or other black swan events. We still want this backstop.
While we know that problem one can be dealt with via machine learned vision models, problem two is more of a reasoning problem, so we were excited by recent advances in language-based reasoning. Problem three is much rarer, so we save that for future work.
To explore this project, we partnered with Google DeepMind and 66 Degrees to develop a cloud-based model that performs tasks one and two. If it works, we’d like to insert such a system into the cloud-based portion of our architecture (Yonder), leaving PickOne untouched, thus avoiding any need to change software or hardware on site. PickOne would still send problematic scenarios to Yonder, but then Yonder would route them to this automated system rather than a human. The AICC would provide the same output as a human would (a single boundary of the next object to pick) which can be passed directly to PickOne.
However, first we need to know if this will work. To experiment, we gathered 6000 examples of human crew-chief solutions to scenarios that our autonomous system found difficult. Each one is an RGB image of the pick area from one of our production cells, and the associated 4-point boundary drawn by the human to indicate the next object to pick to get the system back on track, as shown in green in Figure 1.

Figure 1 – A depalletization example. The blue boundary highlights the area of interest (the pallet), while the green rectangle is the Human CC’s selection for next package to pick. All detected packages are shaded, while the red boundary is the selection from the AICC
The team at 66Degrees took this data and built a Google Cloud hosted project to learn from, and eventually replicate the CC’s decision making process. It was a two step process, combining Meta’s Segment Anything model (SAM2) with Google’s Gemini reasoning.
First, the RGB image was given to SAM2, which generated a set of object segmentation masks (colors in Figure 1). The masks were filtered to remove overly small objects (noise, labels, etc), overly large objects (slip sheets, which are handled separately), and any objects outside of the known pick area. They are then converted to an inscribed quadrilateral, and given to Gemini, which is prompted to select the best object for the next pick. The result is returned as a JSON file, which is in the same format as a Yonder response, and can be consumed by our PickOne system.
To evaluate the system, we must compare it with our baseline, the human crew chiefs. Specifically, there are two measurements we care about: Accuracy and Speed. That is, we want the system to select objects that result in successful picks, as quickly as possible.
To examine accuracy, we look at how often the system-selected object is the same as the crew chief selected one, on a hold-out validation set.
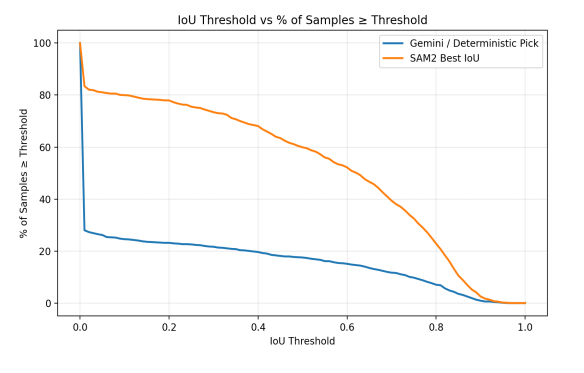
This chart shows the % of samples across the validation set that have a ‘match’ (system-selected object has IOU with crew-chief selected object greater than threshold) for various threshold values. The first thing to notice is that the system-selected object (blue line) never goes above 30%. However, if we look at all of the objects found by the system (after the SAM2 step), we see high percentages, falling off as IOU threshold increases as expected. From this we conclude that the segmentation step does find the same object that the crew chief does, but the reasoning step often chooses something else, as shown in Figure 1.
This looks like a bad result, but remember that the pick ordering and selection process is ambiguous. There are general guidelines, but there generally isn’t a ‘right’ answer in every case. Perhaps Gemini is finding a different, acceptable pick?
To examine this hypothesis, we have expert crew chiefs evaluate the system-generated selections and rate them on if they would be acceptable or not. From this evaluation we find that overwhelmingly they are (80%). However, our crew chiefs top 95% in first pass success, so this is a win for the humans.
Let's consider the timing now. The round-trip time for a Yonder request averages around 10s. Of that, data transfer of the image from the cell to the cloud is just about 4s, meaning that crew chiefs take 6s, on average, to identify the next pick and annotate it.
In the tests with AICC we saw highly variable timing, with means anywhere from 3-7s, and maxes as high as 22s. Most of this time is in the Gemini portion of the system, with SAM2 operating more consistently in about 1.5s. We suspect that the variability of the Gemini portion relates to server load at the time the request is made, but even so, the numbers are not too far off what we get from our humans. We declare this metric to be a tie.
We believe that timing issues can be mitigated, perhaps with dedicated hardware or compressed models. However, the current timing combined with the current accuracy gap means that we cannot let this system operate independently (i.e, directly providing selections to PickOne). Instead, in keeping with our motto of “Robots Work, People Rule", we are exploring incorporating this system as a ‘pre-labeler’ into Yonder, to ease the workload for our CCs as we continue to scale our fleet of production robots, and as we continue to explore the potentials of these technologies.
Learn more about Plus One
